If you’re anything like me, you avoid calling customer service at all costs. The anticipated pain, whether rational or not, of waiting on hold and having to deal with another human interaction is sometimes just too much of a barrier to making a phone call. I often end up using automated chat functions even though they are often far from intelligent. These experiences might lead one to ask, in an age where cars can drive themselves, why are chatbots so often stupid? How can we make them better?
To answer these questions, we (Yuran Wang, Xueming Luo, and Xiaoyi Wang) collaborated with a SaaS company that supplies the provincial government of Zhejiang with a chatbot platform used to answer common questions related to eCertification of local businesses (see working paper here). We argue that, in the standard information retrieval architecture, there exists an inescapable conflict between the size of the bot’s knowledge bank (and hence the bot’s theoretical usefulness) and the bot’s ability to disambiguate free form NLP inputs from the user. This conflict stems from the fact that the retrieval task complexity is increased when user inputs need to be matched to a larger store of potentially useful standard user queries.
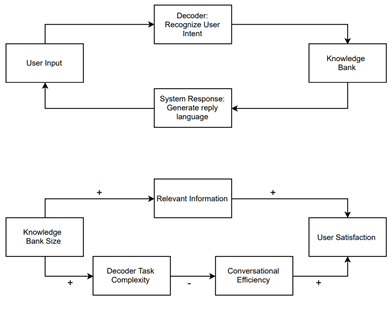
Thus, standard chatbots either don’t have large enough a knowledge base to be useful or often misinterprets the user’s intent, explaining users’ top complaints about commercial applications of chatbots. To solve this problem, chatbot designers typically interject “confirmation dialogues” into the conversation when the bot is unable to disambiguate between several potential queries. While this solution solves the disambiguation problem, it is cumbersome for the user and potentially decreases user satisfaction.
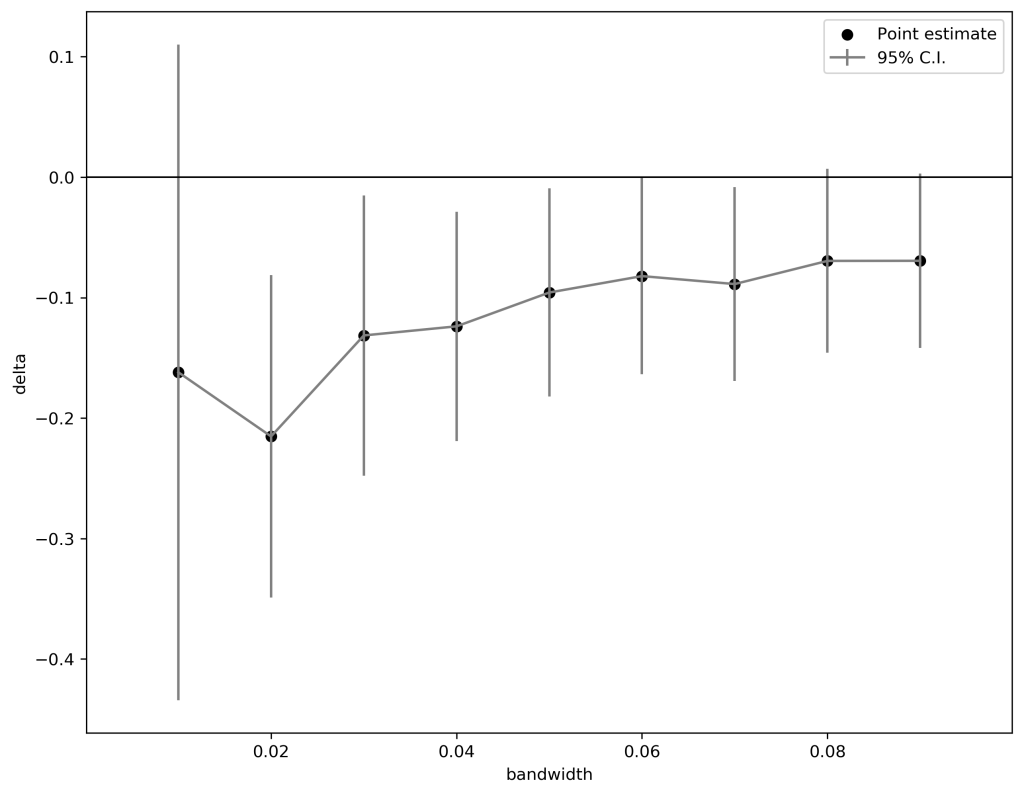
In this study, we quantify the causal impact of confirmation dialogues on user dissatisfaction using a regression discontinuity design (RDD) strategy. The RDD strategy leverages the logical rules used to determine the assignment of confirmation dialogues to compare cases that just missed versus those that just made the cutoff for displaying confirmation dialogue. The figure below shows the estimated difference in satisfaction (y-axis) on a simple 3 point scale (where the average is 1.59/3) versus the bandwidth in the confirmation assignment score generated by the bot’s NLP algorithm around the cutoff point. Here, smaller bandwidth yields more noisy point estimates due to fewer data points, but the idea is that as the bandwidth approaches 0, we approach the true estimate of the hassle costs due to confirmation dialogues. Here, we see a meaningfully large effect size (~ -0.2/3) of the confirmation dialogue’s hassle costs if disambiguation can be avoided.
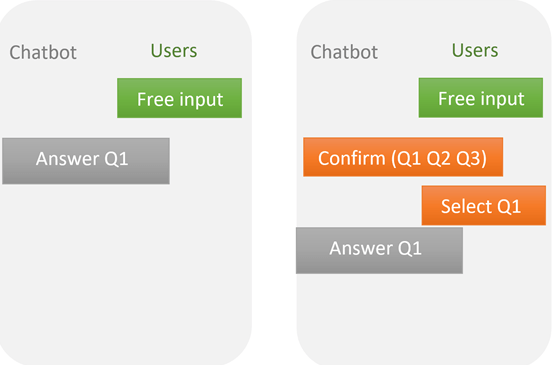
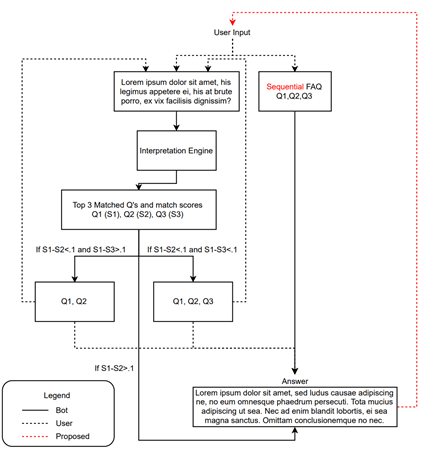
So how can we avoid these types of annoying frictions to conversational efficiency while maintaining a usefully large knowledge bank? Most applications try to resolve this issue by introducing better NLP engines for decoding user inputs. However, even the most state of the art NLP algorithms can only marginally increase the classification accuracy of texts. Therefore, we seek an alternative to the standard brute force approach that addresses the problem by designing a more general artifact to improve conversational efficiency. We simply use the existing sequence of answered queries to predict likely subsequent questions, or sequential FAQ (sFAQ). This approach leverages the hundreds of thousands of existing user query sequences to train a machine anticipate user needs. The machine is then able to predict a substantial proportion of user queries so that no user natural language input (and thus no disambiguation) is needed. We illustrate how sFAQ fits in with the existing chatbot design below, highlighting the additional artifact in red.
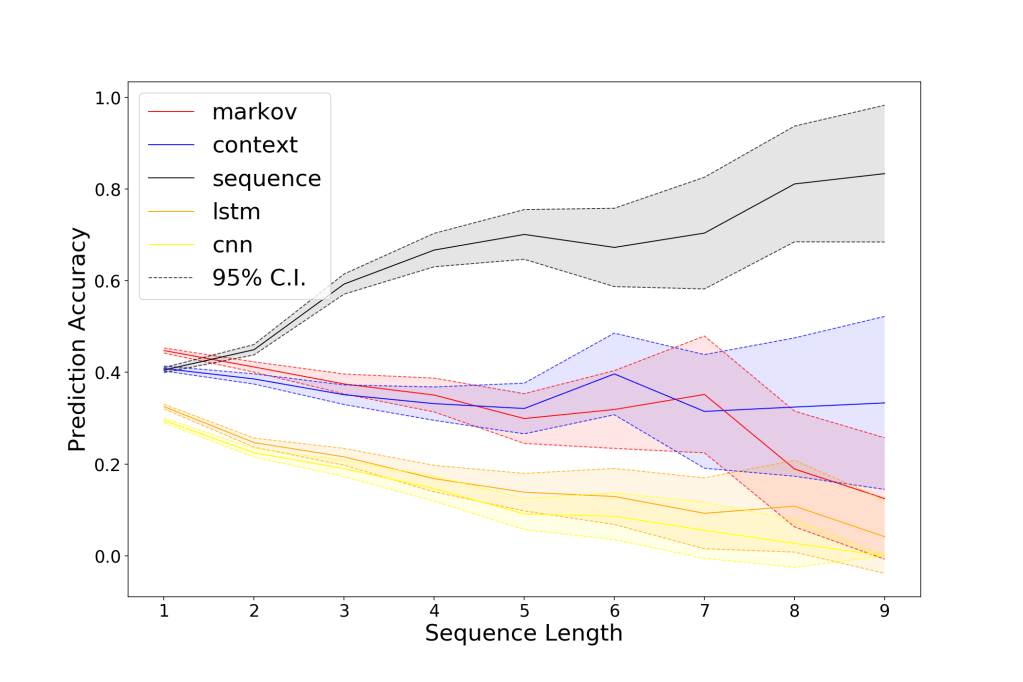
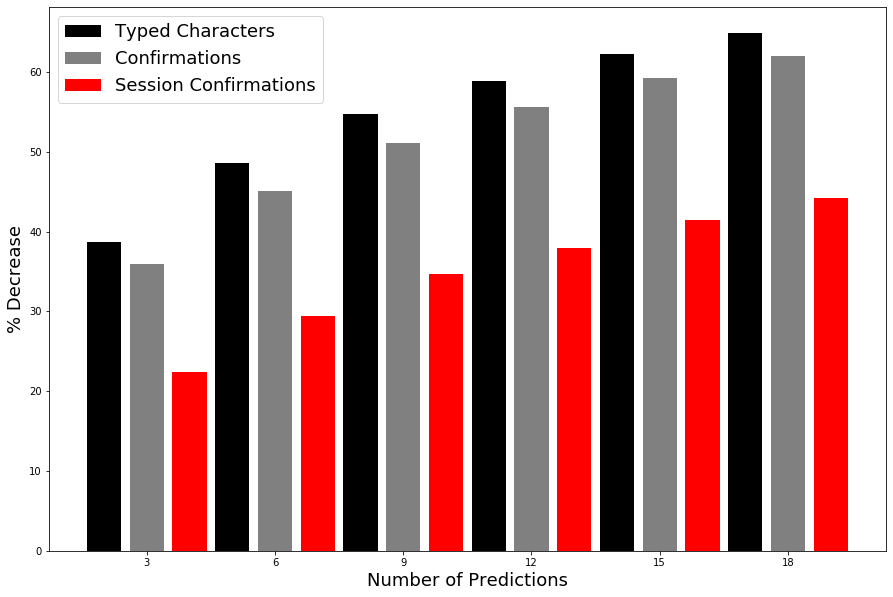
We test several different machine learning architectures to find a good next question prediction engine (see comparisons below). In practice, this sFAQ system automatically suggests 3 questions that the user can choose from. The user is still able to type one of their own questions at any time. We show in out of sample tests that our system, when suggesting 3 questions, would be able to predict the next user query given at least one existing query with an accuracy of 41.8%. Additionally, the system would eliminate 38.7% of all typing, and 35.9% of all confirmation dialogues (currently almost 50% of user inputs are followed by a confirmation dialogue) after the initial query. Combined with our RDD analysis, we can show that the implementation of the sFAQ system would have a causal impact on satisfaction scores through the elimination of confirmation dialogues of at least 2%. We expect the actual increase in user satisfaction to be much higher in future live tests since users will also not have to type. Moreover, our sFAQ system works even better if users are willing to scroll through more than the first set of 3 suggestions.
In short, when a Q&A chatbot such as those used in service settings requires a large knowledge bank to effectively handle user queries, the bot will have difficulty disambiguating the large corpus of intended user queries. sFAQ systems that leverages existing patterns in the query sequences to suggest potential subsequent questions will resolve this design conundrum to a large degree. While we don’t suggest that ours is the best next question prediction engine, we demonstrate that the gains to conversational efficiency are substantial with standard machine learning architectures. Moreover, customers and users will experience less frustration with the chatbot leading to improved satisfaction.
