The previous series of blogs documented how causal inference arguments (difference in differences, regression discontinuity design, and natural experiments) are applied in big data settings within the online reviews domain. This domain also happens to be a great setting to quantitatively analyze textual data. We have a corpus of nearly 18 million reviews for hotels alone. Additionally, we have 8 million manager responses to draw upon. So I will write a series of blogs to touch on some of the things that I am currently working on with these texts data as well as offer an intro to text analysis in Python. In this first blog, I will give a brief overview of some basic text manipulations using a manager response as the example. This is intended as an example for a first hands on course in digital marketing / business computing for a relatively tech savvy student.
To begin, here are some helpful Python packages for text analysis: Gensim, Pattern, TextBlob, and NLTK. For a even more basic setup guide for Python, refer to this blog post. Before analyzing a large corpus of texts, let’s first begin with one example. Take the following manager’s response:
Dear valmtaylor_54, Thank you for choosing The Best Exotic Marigold Hotel as host for your recent stay. I am happy to know you enjoyed your suite and that you were a fan of our robust internet connection. It is really fast! We look forward to hosting you again in the near future. Kind regards, John Smith, Manager. jsmith123@abc123.com
Let’s store this as the variable “response” in Python. What’s interesting about this banal response? Maybe one thing we want to extract is whether or not the response included the username. In our dataset, we have a field for usernames linked to all reviews. Here, username = ‘ValMTaylor_54’
Let’s replace username with a common tag so that any instance of a manager mentioning the username will be easily identified in the text. First, notice that the username in the manager response and the username in our field are inconsistent in terms of capitalization. Let’s first make all the text lowercase.
response = response.lower()
username = username.lower()
Next, replace the username in string with a tag ‘USERNAMETAG’
response = response.replace(username, ‘USERNAMETAG’)
Now our response has been transformed to look like this:

What other information might be useful? Maybe we can look at whether the manager left an email address for contact? This is the perfect place to use a regular expression. (Here’s a great website for learning how to use regex’s). A regex is just a pattern of text that can be systematically detected. An email is the perfect example. Emails are always comprised of a set of contiguous non-blank characters that includes a single ‘@’ and at least one ‘.’ character. Basically, the pattern is roughly the following [SomethingW/OSpacesOr@]@[SomethingW/OSpacesOr@].[SomethingW/OSpacesOr@]
For some basic regex notation. ‘[ ]’ contains a set of characters that represent what we are looking for. ‘^’ means “Not.” So how would we say [SomethingW/OSpacesOr@] in regex?
How about: [^ \t\n@]
This says the set of characters that don’t include ‘ \t\n@’ where ‘ ‘ is a space, ‘\t’ is a tab ‘\n’ is a new line and @ is just @. Now that we identified what character set to look for, we just append * to the end of the set to denote any length string of these characters. Putting it together, we want to find the following regex pattern and tag it as ‘EMAILTAG’:
email_re = r'[^ \t\n@]*@[^ \t\n@]*\.[^ \t\n@]*’
Note here that r just signifies regex. This isn’t necessary, but let’s just stick with convention to make the code more readable.

So far, we’ve learned how to extract some ubiquitous components of a manager’s response from a text. Next, let’s look at how to prepare the text for some basic analysis. First, let’s look at an easy way to split the text into sentences. One way to do this is to specify a set of characters denoting an end of a sentence, such as a ‘.’ and do a response.split(‘.’). An easier way is to use the Textblob package. Textblob converts the text into a blob object that inherits a lot of neat properties.

Maybe one thing we want to compute for each sentence is the grammatical “mood” of each sentence. From our dataset, the 4 moods typically used in a response are: conditional, imperative, indicative, and subjunctive. Refer to wikipedia for what each of these mean. To compute the mood of a sentence, we use the mood function from the pattern.en package.

Note that this response is rather boring in terms of grammatical mood. Also, we added a condition to select only “sentences” with more than one word. While we are at it, we can use Pattern to extract the modality of sentences. Modality represents the “certitude” of a statement. The higher the score, the more factual the sentence. The lower the score, the more wishy-washy the sentence.

Before we analyze the content of the text, we need to first tokenize and preprocess the text to remove as much “garbage” as possible. This is perhaps the biggest “art” portion of textual analysis. Preprocessing is often very subjective and situational. For example, one of the more common things to do in analyzing text is to remove irrelevant or “stop” words. NLTK has a set of common English words that adds little information value:

Note there are many pronouns and uninspiring adjectives. The ‘u’s indicates unicode. One might wonder is it always wise to remove these words? Of course not, but I think in our case, there isn’t too much harm to be done. An alternative common systematic way to find stop words is to remove the most (and maybe least) frequently used x% of words in a corpus.
For now, let’s use the NLTK corpus of English stop words. This can be done using the below bit of code:
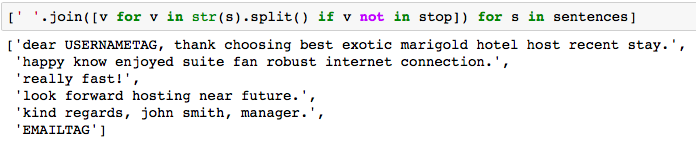
Here, we loop through the sentences from textblob.sentences output. Within each sentence, we loop through the list of words generated by “str(s).split()” and select them if they’re not in the stop list [v for v in str(s).split() if v not in stop] Note that the use of the str(s) type casting is necessary as the sentence object does not inherit the .split() function (it’s a string function that the str type inherits). Finally the code joins the list generated from each sentence as an entry in the output list. The end result is a list of “sentences” without stop words.
Finally, let’s remove unnecessary punctuation. The fastest way to do this is using the str.translate function. This function does a character by character replacement and allows you to exclude a list of characters from the output. Being a native python function optimized in C, this should be the fastest way to remove characters.
As we demonstrate the stripping of punctuation, this might be a great time introduce functions in python. A function is basically a reusable bit of script that takes an input and gives an output. We will write a short function to accomplish the stripping task. I’ll also take this opportunity demonstrate timing code in ipython notebook and improving execution speed.

Note that we wrote 2 functions here: _strip_punc_ and _strip_punc2_ Both take argument ‘s’ which is expected to be a string and outputs a new string without punctuations. We get a list of punctuations from the string module. We also import the functions translate and maketrans. Maketrans creates a hash table from character to character, it is a necessary argument for the translate function. We create basically a null table because we don’t want to do any character replacements. However, the second argument in translate is a list of exclusion characters. Here, we use the punctuation list we imported. Note the only difference between the 2 functions is that we import the necessary bits outside of the function in _strip_punc2_. By doing this, we avoid having to import these modules every time the function is executed in the list literal (which is a loop through sentences). The end result is a 3-4 x improvement in speed.
